

Vous n'êtes pas identifié(e).
Bonjour Julien et merci de votre réponse.
J'ai tenté de créer un jeu de données quasiment iso en volumétrie et structure > https://1fichier.com/?bx1vzax1twrsioxsl5fi
Et voici la requête adaptée > https://1fichier.com/?jboe86m6mm69paaszlbv
En parallèle de ça j'ai analysé le résultat via explain DALIBO : https://explain.dalibo.com/plan/13a7h14fb882be93 mais le chemin ne correspond pas au chemin parcouru par la requête avec de "vrais" données. Voici à quoi ressemble le parcours de la requête sur la vraie donnée :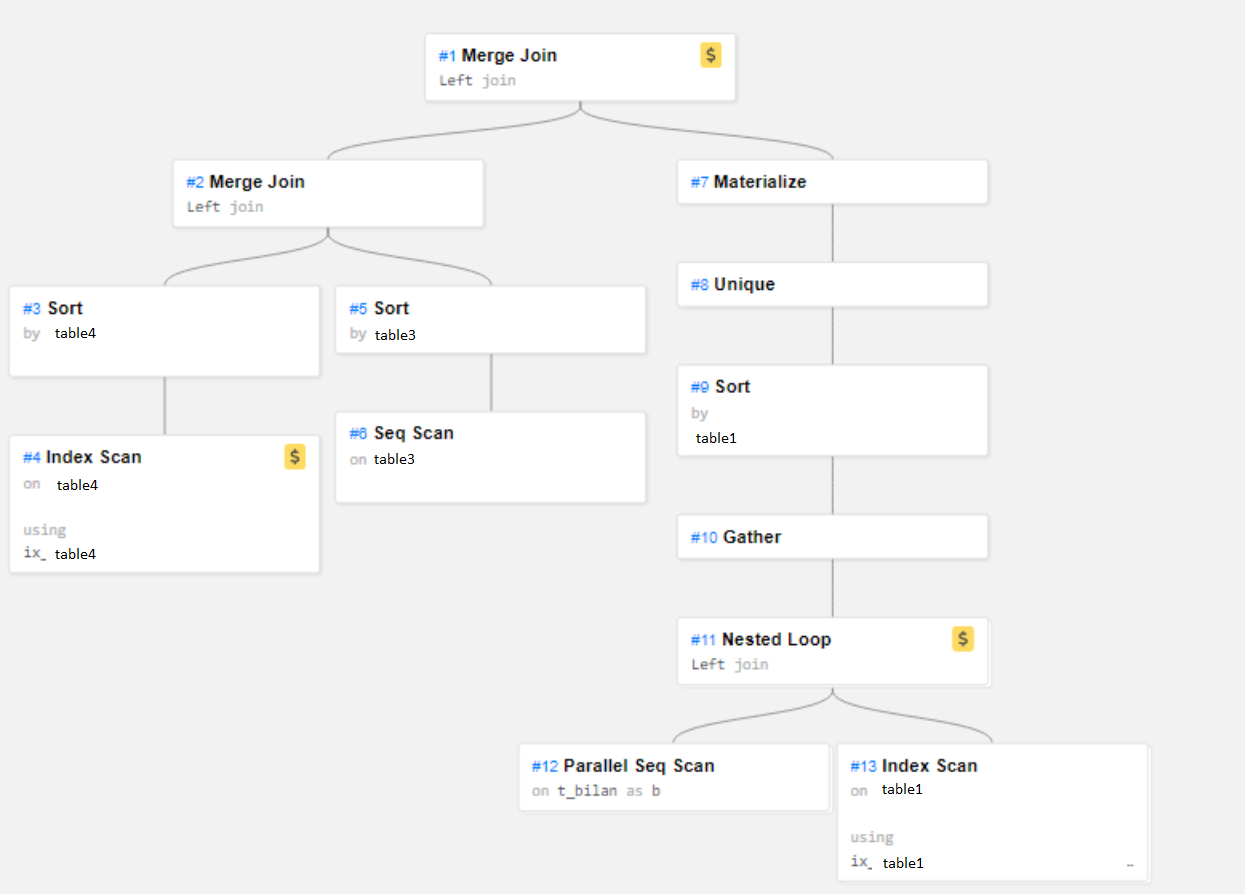
Merci de votre aide.
Bonjour à tous,
Je pensais jusqu'à aujourd'hui, que les clés étrangères déclarées dans une table postgres étaient automatiquement indexées, puis, je suis tombé sur une option dans PG Admin : Index FK Auto. Par conséquent, qu'en est-il ?
Si je suis bien votre (complète) documentation (https://public.dalibo.com/exports/forma … ndout.html) la clé est indexée si, dans la table à laquelle elle fait référence, cette même clé correspond à une clé primaire.
En l’occurrence, j'ai un cas qui ne semble pas être le même et je ne sais pas comment je pourrais optimiser mon indexation. Dans mon cas ma clé étrangère est un champ à part dans l'autre table :
A noter : la table 1 contient une contrainte d'unicité sur le champ ID_Table2
Comment puis-je optimiser cela ?
Merci
Geo-x
Bonjour rjuju,
Il s’agit de connaître le nombre d’INSERT et d’UPDATE sur une plage horaire donnée.
Bonjour @ tous,
Serait-il possible de récupérer le nombre de transactions sur une table donnée ?
J'ai testé depuis la table pg_stat_activity mais elle ne semble pas contenir grand chose.
Merci.
Geo-x
C'est côté client, mais j'ai quand même eu accès à certains logs et j'ai ce message en masse : LOG: unexpected EOF on client connection with an open transaction
ça veut dire que les connexions ne sont pas fermées c'est bien ça ?
Ah d'accord, je ne savais pas, je suis actuellement en version : PostgreSQL 10.18 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 7.3.1 20180712 (Red Hat 7.3.1-12), 64-bit
Comment puis-je savoir si l'autovacuum est activé ? Si dans PgAdmin je clique sur la base > Maintenance, je ne le vois pas activé.
Je n'ai pas encore mis en place l'AUTO VACUUM, c'était une question en amont :-)
Pour le moment je fais les VACUUM manuellement.
Sur les dizaine de milliers de nouveaux enregistrements, il s'agit d'un mix insertion/mises à jour, et non chaque ligne ne fait pas plusieurs centaines de Mo. Pour donner un ordre d'idée j'ai 495 000 enregistrements pour un poids total 29 Go soit environ 0,05 Mo / ligne.
Bonjour,
1/ Les timeout viennent précisément de ces requêtes parfois trop nombreuses simultanément
2/ Etant donné que c'est une API que j'ai mis en place, je ne vois pas les erreurs
3/ 8gib de mémoire + 1 processeur Intel Xeon Platinum 8175 2vCPUs c'est du 64 bits
4/ Etant donné que c'est du cloud, pas forcément ...
C'est la même table que pour mon autre sujet en réalité :-) (https://forums.postgresql.fr/viewtopic. … 724#p33724)
Il n'y a pas forcément de grosses baisses de performances à ce stade, en revanche la volumétrie est conséquente (plusieurs dizaine de milliers d'enregistrements quotidiens)
Bonjour @ tous,
Je rencontre quelques problèmes de timeout sur Postgres lors d'insertion et de mises à jour via APIs.
La volumétrie est importante (33 174 requêtes en 15 minutes avec un pic de 4718 requêtes en 1 minute).
Est-il possible de jouer sur quelques paramètres de Postgres pour accepter ces nombreux flux entrants.
Merci de votre aide.
Geo-X
Bonjour à tous,
J'ai une question toutes simple à la quelle je ne trouve pas forcément de réponse.
Sur une table contenant plusieurs centaine de milliers d'enregistrements, mis à jour quotidiennement en nombre (plusieurs dizaine de milliers) il me semble indispensable de mettre en place un AUTO VACUUM quotidien.
Ma question porte sur la ré indexation.
Etant donné que l'AUTO VACUUM va nettoyer les lignes cachés, j'imagine que ces lignes étaient indexées.
De fait, est-il nécessaire de lancer une réindexation à chaque VACUUM (auto ou pas) réalisé ?
Merci.
Geo-x
Bonjour rjuju,
Voici un exemple peut-être plus parlant que mes plats régionaux :

Bonjour à toutes et à tous,
Je me posais une question de modélisation, est-ce envisageable / correct pour faire un lien entre deux tables, d'utiliser une clé primaire équivalente pour des enregistrements associés.
Cet exemple très parlant :-)

Merci d'avance.
Geo-x
Bonjour Julien et merci de votre réponse.
En réalité je l'ai fait :

Mais une fois que j'ai sauvegardé, le droit a aussitôt disparu :

Bonjour @ tous.
J'essaie de donner accès à une fonction présente dans le schéma public au user myuser qui ne doit pas avoir accès à tout le schéma public .
Pour cela je lui ai donné accès à la fonction (ça a fonctionné sur d'autres fonctions)
Le problème c'est que lorsque l'utilisateur essaie d'utiliser cette dernière le message suivant apparaît :
ERROR: permission denied for schema public
LINE 1: SELECT public.myfunction(myinteger...Autre solution testée :
J'ai essayé à tout hasard de récupérer cette fonction et de l'intégrer à un schéma dont l'utilisateur est le propriétaire mais là, la fonction ne fonctionne plus du tout (il me dit que la fonction n'existe pas).
Merci de votre aide.
Geo-x
Ok c'est bon, pour information, j'ai attribué mon nouveau_user en tant que propriétaire sur les deux schémas à modifier.
De fait mon user_proprietaire historique qui hérite des droits du superuser, continue à pouvoir faire des ALTER sur ces mêmes schémas.
C'est donc une affaire résolu, merci beaucoup de votre précieuse aide.
Geo-x
Bonjour Guillaume.
En effet en faisant un
GRANT ROLE user_proprietaire TO nouveau_user;Ca fonctionne, sauf que maintenant nouveau_user a accès à beaucoup de choses, il ne me reste plus qu'à restreindre.
Merci pour cette précieuse requête.
Cependant comme je vous disais je cherche à voir qui a les droits pour attribuer par exemple le droit de faire des ALTER (sans mauvais jeu de mot niveau muscu) ou bien qui a accès à des fonctions.
Là c'est plus compliqué puisque mon besoin est le suivant :
> utiliser les fonctions du schéma dans lequel elle a accès + le schéma public
> Créer ou modifier des tabes et des vues sur un schéma spécifique
Ce n'est peut-être pas possible en fait.
Bonjour rjuju et merci de votre réponse.
Je vois le problème, comment pourrais-je faire pour visualiser les droits d'attribuer des droits (pas forcément table par table) ?
Bonjour @ tous.
Je rencontre de grosses difficultés pour attribuer à un utilisateur le droit de création/modification de table et également au niveau de l'utilisation des fonctions, j'ai toujours ceci qui s'affiche lorsque j'essaie d'attribuer les droits :
WARNING: no privileges were granted for "unaccent_init"
WARNING: no privileges were granted for "unaccent_lexize"J'ai contrôlé les droits du rôle qui me semblent bon :
J'ai contrôlé les droits sur pg_database et j'ai ceci :
{group=CTc/group,monuser=c/group}Lorsque je regarde sur pg_class sur une table cible pour contrôler, j'ai ceci :
{admin=a*r*w*d*D*x*t*/monuser=arwdDxt/admin}De mon côté ce que je souhaite c'est que le user monuser puisse :
> utiliser les fonctions du schéma dans lequel elle a accès + le schéma public
> Créer ou modifier des tabes et des vues sur un schéma spécifique
Est-ce que vous auriez une idée de ce qui bloque ?
Merci d'avance de votre aide.
Geo-x
Merci de ce retour.
Oui en effet l'objet est sur plusieurs niveaux et est amené à être modifié.
Là je suis en train de faire un test ou mon objet serait :
{
"uuid": uuid,
"date_create": timestamp with time zone,
"date_start": timestamp with time zone,
"date_end": timestamp with time zone,
"statut": character varying,
"version": character varying,
"description": character varying,
"ref_externe": character varying,
"key_duck": character varying,
"type_data": jsonb{},
"type_object": jsonb{},
"timeline": jsonb{},
"document": jsonb{},
"sub_object": jsonb[]
}Bonjour Guillaume et merci de votre réponse.
Dans ce cas, il vaut mieux privilégier le format jsonb c'est ce qu'il me semblait :-)
Dans l'exemple explicité dans l'introduction du sujet, on peut remarquer des sous-sous-sous-sous-sous niveaux. En terme d'architecture, sur la documentation officielle, je ne vois pas spécialement d'optimisation requises. Ceci veut donc dire que je peux intégrer mes sous-niveaux directement dans un champ dès le niveau 2 ? Même si c'est un ARRAY ?
Bonsoir dverite.
Merci de cette traduction :-) En effet ça me parait pertinent.
Pour les json, en revanche, de ce que je comprends en utilisant des champs de type jsonb, l'indexation est automatique, cela rentre dans le champ de ce que vous précisez ? ( à savoir une modification de structure fou tout en l'air)
Merci
Bonjour @ tous.
Visiblement peu de gens utilisent Postgres comme une base NOsql (。◕‿◕。)
Juste pour avancer sur ce sujet, j'ai continué de lire la documentation et je suis tombé sur ce chapitre qui m'est apparu intéressant :
8.14.2. Concevoir des documents JSON efficacement
Représenter des données en JSON peut être considérablement plus flexible que le modèle de données relationnel traditionnel, qui est contraignant dans des environnements où les exigences sont souples. Il est tout à fait possible que ces deux approches puissent coexister, et qu'elles soient complémentaires au sein de la même application. Toutefois, même pour les applications où on désire le maximum de flexibilité, il est toujours recommandé que les documents JSON aient une structure quelque peu fixée. La structure est typiquement non vérifiée (bien que vérifier des règles métier de manière déclarative soit possible), mais le fait d'avoir une structure prévisible rend plus facile l'écriture de requêtes qui résument utilement un ensemble de « documents » (datums) dans une table.
Les données JSON sont sujettes aux mêmes considérations de contrôle de concurrence que pour n'importe quel autre type de données quand elles sont stockées en table. Même si stocker de gros documents est prévisible, il faut garder à l'esprit que chaque mise à jour acquiert un verrou de niveau ligne sur toute la ligne. Il faut envisager de limiter les documents JSON à une taille gérable pour réduire les contentions sur verrou lors des transactions en mise à jour. Idéalement, les documents JSON devraient chacun représenter une donnée atomique, que les règles métiers imposent de ne pas pouvoir subdiviser en données plus petites qui pourraient être modifiées séparément.Le problème, c'est que je ne suis pas certain de comprendre, concrètement, à quoi cela peut ressembler au final (surtout le terme de donnée atomique ఠ_ఠ )
Une idée ?
Merci de votre aide.
Geo-x
Bonjour @ tous.
J'aurais aimé quelques conseils concernant les bases NOsql je m'explique.
Je cherche une technologie de base NOsql un peu "hybride" qui me donne les avantages d'une base NOsql (lecture/écriture de masse efficace, enregistrement d'objets simplifiés (array,json...)) et une partie des BDD relationnelles (facilitation de requêtage entre autre), et c'est tout naturellement que j'ai pensé à Postgres.
Voici le genre d'objet que j'ai aujourd'hui dans ma BDD NOsql "classique" :
{
"uuid",
"date_create",
"date_start",
"date_end",
"statut",
"version",
"description",
"ref_externe",
"key_duck",
"type_data": {
"uuid",
"code",
"description"
},
"type_object": {
"uuid",
"code",
"description"
},
"timeline": {
"day",
"month",
"year"
},
"document": {
"description",
"url"
},
"sub_object": [{
"uuid",
"number",
"type_datas": {
"uuid",
"code",
"description"
},
"type_objects": {
"uuid",
"code",
"description"
},
"number_sub",
"description",
"sub_sub_object_array": [{
"sub_sub_sub_object1_array": [{
"uuid",
"code",
"description"
},
...
],
"sub_sub_sub_object2_array": [{
"code",
"description",
"my_json": {
"uuid",
"code"
}
},
...
],
},
...
],
"sub_sub_object_json1": {
"uuid",
"code",
"libelle",
"segment_tva"
},
"sub_sub_object_json2": {
"uuid",
"code",
"description",
"sub_sub_sub_object_json": {
"sub_sub_sub_sub_object_json": {
"uuid",
"code",
"description"
},
"sub_sub_sub_sub_object_array": [{
"code",
"number"
},
...
],
},
}
},
...
]
}Sur ce type d'objet, j'ai besoin de pouvoir faire des recherches sur des objets imbriqués et donc d'avoir des indexations efficaces.
J'ai donc deux questions (pour commencer) :
1/ ce format là d'enregistrement est-il adapté à une base de données comme Postgres en mode NOsql ? (en gros à partir de sub_object on met l'objet dans une colonne jsonb)
2/ Vaut-il mieux privilégier des objets très imbriqués comme cela ou bien vaut-il mieux créer autant de tables qu'il y a de sous-objets ?
Merci de vos retours (et même s'il s'agit de retours d'expériences hors des deux questions, je suis évidemment preneur)
Geo-x